Document Ingest and Processing Pipeline for Swedish News Agency
Modernizing legal document ingestion and archival with an event-driven, serverless architecture
LiteBreeze helped Actapublica modernize its outdated, non-scalable document processing system. Robotea, the new solution, built on AWS, improved throughput, reduced infrastructure costs, and gave editorial teams faster access to archived content.
Client Overview
The client is a Swedish news agency operating in the journalism and legal document archiving sector.
- Acts as a national source of legal news and documents
- Maintains a real-time searchable archive of legal records
- Supports both media professionals and public users through timely reporting and easy access to legal documentation
Business Challenge
The agency’s workflow involved:
- Collecting and archiving legal documents from various Swedish government agencies
- Processing scanned PDFs through OCR pipelines to extract text
- Indexing documents into Elasticsearch for search and archival
- Enriching metadata (region, type, authority) — partly via Amazon Mechanical Turk (MTurk)
- Making the enriched archive accessible to editorial teams and the public
However, their legacy PHP-based system created several issues:
- Loosely connected scripts worked sequentially, creating bottlenecks
- Single-threaded design caused slow processing and frequent backlogs
- Could not keep up with the growing volume of incoming documents
- Editorial teams faced delays in reporting due to late document availability
The solution: Robotea
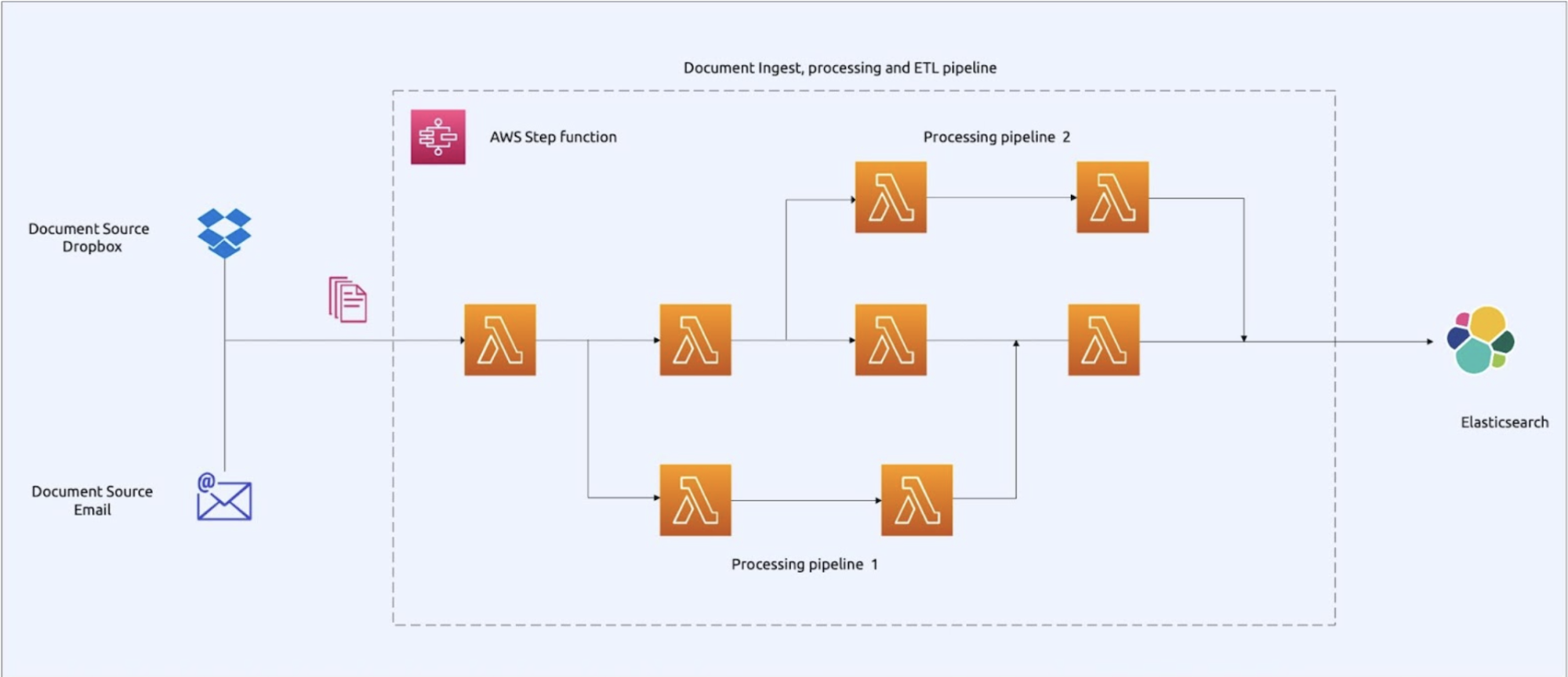
LiteBreeze re-architected the pipeline into a modular, serverless, event-driven system on AWS:
- AWS Lambda (Python) replaced sequential scripts, enabling parallel execution
- Workflow steps (ingestion, OCR, metadata extraction, indexing) were decoupled and orchestrated via AWS Step Functions
- Built-in error handling, retries, and notifications improved reliability
- Serverless design removed infrastructure management, cutting operational overhead
This allowed the client to achieve immediate scalability and handle high volumes efficiently.
Implementation Process
The migration was phased to minimize risk:
- Pilot Phase → Rebuilt only the ingestion module in AWS Lambda to test feasibility
- Expansion Phase → Gradually integrated OCR, metadata, and indexing into separate Step Functions
- Automation → Infrastructure provisioned via AWS SAM (Serverless Application Model) and CloudFormation for version-controlled deployments
- Cutover → Full production switch after successful staging validation, with minimal disruption
Results and Benefits
The new system delivered measurable improvements:
- Scalability: From a few hundred → ~10,000 documents per day
- Flexibility: Handled both steady ingestion and sudden spikes in volume
- Cost Efficiency: Serverless design scaled down during off-peak hours, reducing costs
- Observability: AWS CloudWatch + Slack alerts improved visibility and incident response
Editorial workflows became faster, more reliable, and cost-efficient.
Conclusion
By moving to a serverless, event-driven architecture on AWS, ActaPublica:
- Eliminated backlogs from sequential processing
- Achieved high-concurrency document handling
- Reduced operational costs with on-demand scaling
- Gained better monitoring and real-time alerting
This project established a scalable, resilient, and cost-effective foundation for ongoing document ingestion and archival.
Technologies Used
- Programming Language: Python
- Serverless Compute and Workflow Orchestration: AWS Lambda, AWS Step Functions
- Document Processing and OCR: AWS Textract
- Search and Indexing: Elasticsearch
- Relational Data Storage: AWS RDS
- Crowdsourced Metadata Extraction: AWS Mechanical Turk (MTurk)
- Monitoring and Alerts: AWS CloudWatch, Slack integration
- Infrastructure as Code: AWS Serverless Application Model (SAM)